While learning Python, I became very interested in web scraping and decided to try it myself. Of course, the course I found on YouTube wasn't very detailed, but I'm very grateful to the PythonHubStudio and PythonToday channels for the material and for all the work they put into the tutorial videos. To learn more about web scraping, I also relied on the documentation for the requests and beautifulsoup4 libraries.
I developed a sophisticated three-phase web scraping pipeline. This system efficiently collects product data from e-commerce catalogs while maintaining ethical scraping practices.
Tech Stack: Python, Requests, BeautifulSoup4, Pandas, XlsxWriter, Glob, Time, Random
Technical Implementation

- HTTP Request Management: Proper headers, timeouts, and status code handling
- DOM Navigation: Efficient element selection with CSS classes and attributes
- Data Processing: Structured data transformation and export to Excel
- Error Handling: Comprehensive exception management with detailed logging
Resilient Page Downloading

- Rate Limiting: Strategic delays to respect server resources
- File Operations: Efficient file I/O with proper encoding handling
- Content Preservation: Raw HTML storage for debugging and re-processing
- Progress Tracking: Real-time logging for operational transparency
Data Extraction & Transformation

- Complex Parsing: Multi-level DOM traversal with fallback mechanisms
- Data Cleaning: Text normalization and formatting consistency
- Excel Automation: Programmatic spreadsheet generation with formatting
- Batch Processing: Efficient handling of multiple data sources
The challenges I faced
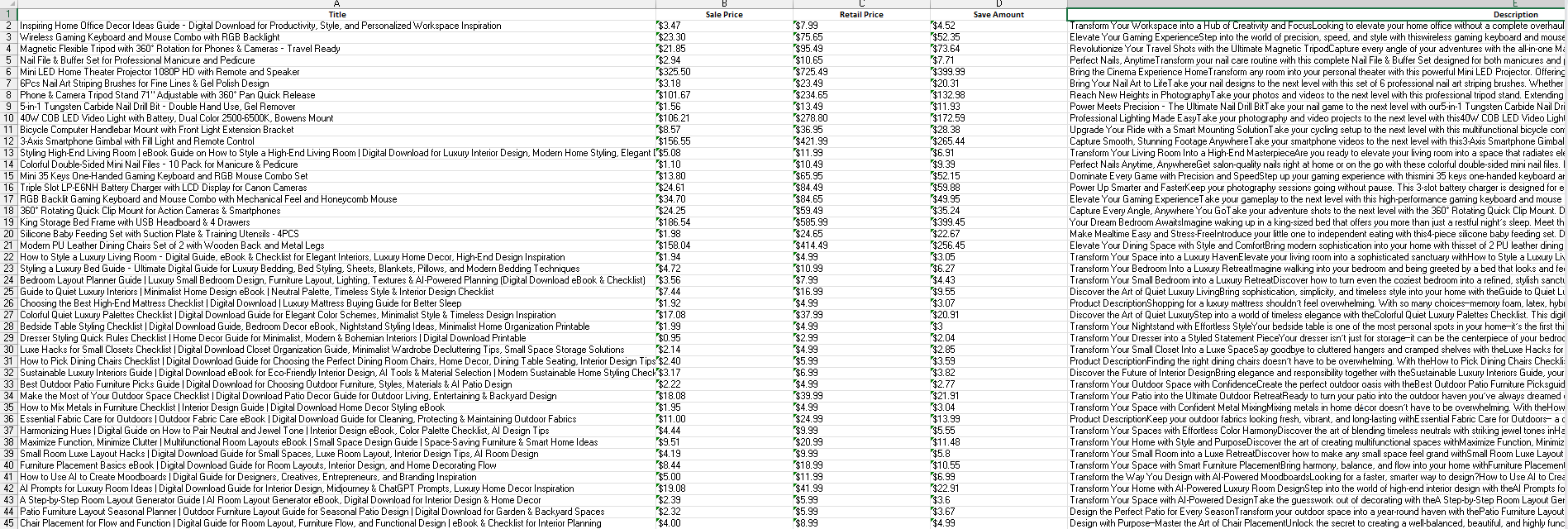
Of course, there were difficulties in the creation process. Some of them were related to the site structure and hidden elements. So, in order to avoid sending unnecessary HTTP requests, I created a skeleton and tested it on the books.toscrape.com site, and only then did I start making edits for sellviacatalog. And again, even if the site allows parsing, I decided to first download all the pages to local storage and parse them from there.
And in the screenshot above, you can see the result I got. Output to an Excel file.